





Study population
Portable EEG data were obtained from 294 participants (122 healthy volunteers (HVs) and 172 patients) at the Osaka University Hospital.
The HVs were community-dwelling older adults and selected based on the following inclusion criteria: (1) no history of neurological or psychiatric diseases, (2) no history of severe head injury or alcohol/drug abuse, and (3) no impairment of daily living or global cognitive impairment (Mini-Mental State Examination (MMSE)23 score ≥ 27), as in our previous study15.
All patients underwent baseline assessments, including demographic, cognitive, and neuropsychiatric assessments; brain structure assessments using MRI or computed tomography; and laboratory measurements (e.g., blood cell count, blood chemistry measurements, thyroid hormone levels, vitamin B1, B12, and folic acid). The recruitment period was from April 2021 to February 2024. The following examinations were optionally performed according to the attending physician’s judgement: SPECT, CSF markers, MIBG myocardial scintigraphy, DAT uptake in the basal ganglia, and PSG. Based on these examinations, the patients were evaluated through expert conferences to determine their clinical diagnoses based on international criteria, and subsequent treatment plans. As in our previous study15, this study included three dementia-related diseases: AD, Lewy body disease (LBD), and idiopathic normal-pressure hydrocephalus (iNPH). The patient details are described below.
Patients with AD were diagnosed according to international criteria24,25, those with LBD based on standard diagnostic consensus criteria8,26, and those with iNPH met standard criteria27. The diagnoses of LBD and iNPH were prioritized over those of AD in patients considered to have LBD or iNPH with comorbid AD24. In addition, as a consequence of the expert conference, patients in whom a specific neurodegenerative or dementia-related disease could not be identified as the underlying pathology were included as “non-specific.”
Regarding cognitive function, this study enrolled patients with MCI and dementia. Dementia severity was assessed based on the clinical dementia rating (CDR)28. In subsequent analyses, we considered MCI to have a CDR of 0.5 according to a previous study29, mild dementia to have a CDR of 128, and moderate dementia to have a CDR of 228.
Under these conditions, the final analysis included 119 HVs and 114 patients. The 114 patients included 45 with MCI, 48 with mild dementia, and 21 with moderate dementia when categorized by severity, while diagnosis included 53 with AD, 32 with LBD, 22 with iNPH, and 7 with non-specific MCI when categorized by clinical diagnosis. The demographic and clinical information of the HVs and patients is summarized by severity in Table 1 and by clinical diagnoses in Table 2.
Ethics
This study was conducted in accordance with the principles of the Declaration of Helsinki, approved by the Ethics Review Committee of Osaka University Hospital, and registered in the UMIN Clinical Trial Registry (UMIN 000042903). Before enrollment, each participant received both written and verbal explanations of the study objectives, procedures, potential risks and benefits, and the measures for data protection and privacy. Written informed consent was obtained for participation, and the participants were informed that their participation was voluntary and that they could withdraw their consent at any point without any impact on their care.
A patch-type portable EEG sensor
EEG measurements were performed using a portable, patch-type EEG device, HARU-1 (Supplementary Fig. 1 (S1); PGV Inc., Tokyo, Japan). The HARU-1 has received medical approval from Japan’s Pharmaceuticals and Medical Devices Agency (PMDA) and has been evaluated using the same standards as traditional clinical EEGs (Certification Number: 302AFBZX00079000, class II). The EEG signals were measured using three channels, the ChZ (center), ChR (right), and ChL (left), with a sampling frequency of 250 Hz. The specifications of the wireless sensing device and the electrode sheet are listed in Supplementary Table 1 (S2) and 2 (S3), respectively.
The device was lightweight, weighing only 27 g, and had a curved shape designed to fit the user’s forehead comfortably. Its Li-ion battery, with a capacity of 200 mAh, was chargeable via a micro-USB connector and lasted for approximately 12 h in recording mode. The wireless communication interface was based on the Bluetooth Low Energy (BLE) protocol, which provides easy device control. The HARU-1 device boasted a high voltage resolution of up to 24 bits (22 nV/LSB) and low input-referred noise of 1 µVpp.
The disposable electrode sheets (Notification Number: 13B2X10421000001, class I) of the device had a thickness of < 50 μm, stretchability of up to 200%, and a moisture permeability of 2700 g/m²/day. These sheets were manufactured using a screen-printing process with a biocompatible gel on an elastic base and a silver-based material. The biocompatibility of the conductive and nonconductive gels used in these electrode sheets was assessed in accordance with the ISO 10,993 standards for skin sensitization, irritation, and in vitro cytotoxicity.
EEG preprocessing
The analysis used resting-state EEG data with eyes closed. As part of the data preprocessing, a 0.5–95 Hz band-pass filter was applied to capture a broad range of clinically-relevant EEG frequencies, from delta to gamma bands, while reducing the slow drifts and high-frequency noise. Given the variations in local power supply frequencies, notch filters at 50 and 60 Hz were included to attenuate power line interference and its harmonics. The filtered EEG data were subjected to short-term Fourier transform (STFT) to analyze the frequency content over time30. The STFT was computed using the following parameters: Hamming window, segment length (\(\:{n}_{perseg}\)) of 8 s (2000 samples), overlap (\(\:{n}_{overlap}\)) of 7 s (1750 samples), and FFT length (\(\:{n}_{fft}\)) of 2048 points.
The STFT was defined as follows:
$$\:\begin{array}{c}STFT\left\{x\left(t\right)\right\}\left(t,f\right)={\sum\:}_{m=-\infty\:}^{\infty\:}x\left[m\right]w\left[m-t\right]{e}^{-j2\pi\:fm}\end{array}$$
where \(\:x\left(t\right)\) represents the signal, \(\:w\left(t\right)\) is the Hamming window function, \(\:t\) is the time, and \(\:f\) is frequency. The Hamming window helps minimize the spectral leakage.
In this study, the segment length was set to 8 s, allowing for a detailed frequency analysis while maintaining adequate time resolution. An overlap of 7 s ensured a high degree of temporal continuity between the segments, further enhancing the resolution of transient events in the EEG data. An FFT length of 2048 points provided a high-resolution frequency spectrum, facilitating the detection of subtle changes in EEG signals.
After applying the STFT, the axes were rearranged and the absolute values of the amplitude spectra were obtained. Because the frequency features are given by \(\:{n}_{fft}/2\) +1, this results in 1025 frequency bins. Finally, the 2-min EEG data for each participant were transformed into frequency features with dimensions of 108 × 1025 × 3, where 108 is the number of 8-s epochs, 1025 is the number of frequency bins, and 3 is the number of channels.
Data splitting
First, the dataset was divided into cross-validation and holdout datasets at a 0.9 to 0.1 ratio. Owing to this split, the holdout dataset included 12 HVs and 12 patients, whereas the cross-validation dataset included 107 HVs and 102 patients. Within the cross-validation dataset, the data was further split into training and validation sets in a 0.9 to 0.1 ratio. A 10-fold cross-validation method was employed, applying the Stratified K Fold31 to ensure that the distribution of diseases and CDR was consistent across all folds, thus minimizing bias.
Model architecture
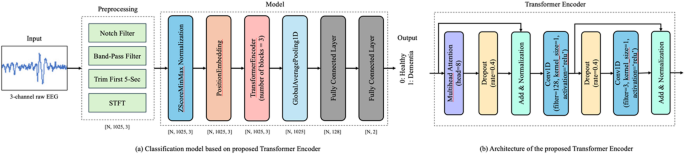
A transformer-encoder-based model was deployed to perform the classification task. The architecture of the model is illustrated in Fig. 1. The model architecture is based on a customized transformer encoder. However, several modifications were made to the standard transformer encoder32, to facilitate the extraction of features from the 3-channel EEG data. The modifications are as follows:

Model Architecture. This figure illustrates the architecture of the EEG classification model built using a customized transformer encoder. (a) Overview of the classification pipeline. Resting-state EEG data recorded with the eyes closed were preprocessed by applying bandpass and notch filters to remove low-frequency drifts and power line noise. Short-time Fourier transform (STFT) was subsequently applied to extract the time-frequency features. The resulting spectral features were input into the model, which outputted the class probabilities corresponding to the cognitive status (i.e., healthy or patients). (b) The internal structure of the transformer encoder. The model employs three parallel transformer encoder blocks, each consisting of a multi-head attention mechanism followed by a convolutional feedforward network using 1D convolutional layers. Dropout was applied at multiple stages to prevent overfitting, and layer normalization was applied to stabilize the training. ‘N’ denotes the batch size.
First, three parallel transformer encoder blocks were used instead of a single transformer encoder. This parallelization allows the model to capture diverse features from the input data, thereby enhancing its robustness and accuracy. In addition, the traditional feedforward network is replaced with a convolutional feedforward network using Conv1D layers33. This change enhances the ability of the model to capture local dependencies in the data, making it particularly useful for learning inter-channel relationships in time-series data. Furthermore, to prevent overfitting, enhanced dropout regularization34 was applied at multiple stages within each transformer encoder block. This improved the generalization performance of the model for unseen data. Finally, as in the conventional architecture, layer normalization was applied after both the multihead attention mechanism and feedforward network. This step is crucial for stabilizing the training process and ensuring a faster convergence. Using these customizations, the model was effectively adapted to extract features from 3-channel EEG data.
Model training
We conducted a 10-fold cross-validation, resulting in the creation of 10 models35. In each fold, 90% of the dataset was used for training, and the remaining 10% was used for validation. An ADAM36 optimizer with a learning rate of 0.0001 was used for each cross-validation. To prevent overfitting, an early stopping mechanism was introduced. Specifically, if no improvement in the validation metrics was observed for 50 consecutive epochs, training was halted and the best weights observed during training were restored37.
In each fold, features were generated per participant with 108 epochs of features created per participant. The epochwise features of the entire training dataset were concatenated, randomly shuffled to avoid order dependency during training, and fed into the model using a batch size of 32. This approach ensured the integrity and reliability of the data. To maintain consistency, the data were not shuffled during the calculation of the validation metrics.
The transformer model comprises approximately 199,995 trainable parameters. Dropout regularization was applied after each encoder block, and early stopping at 50 epochs was applied to prevent overfitting. Weight decay was further implemented by regularizing the optimizer. Additionally, data augmentation using the MixUp method (α = 0.6, probability = 0.8)38 was applied during training.
The main libraries and their versions used in the training process were numpy39 version 1.24.3, scipy40 version 1.12.0, and TensorFlow41 version 2.13.0.
The performance of the model was comprehensively evaluated using this setup,, and its robustness and reliability were confirmed.
Model inference
Model outputs were generated per epoch, and the epoch-wise results were averaged for each participant to obtain participant-level results. In the evaluation of the 10-fold cross-validation dataset, the results for each participant in the validation dataset of each fold were aggregated to assess the overall performance. An ensemble method was adopted to evaluate the holdout dataset by averaging the outputs of the ten models trained through cross-validation. Specifically, we averaged the epochwise results for each participant and further averaged the output results of each of the 10-fold models to obtain the results for the holdout participants.
Evaluation metrics
For the binary classification task of distinguishing between the HVs and patients, we employed several evaluation metrics to comprehensively assess the performance of our model. The selected metrics included the sensitivity, specificity, balanced accuracy (bACC), and area under the receiver operating characteristic (ROC) curve (AUC)42,43. bACC was calculated as:
$$\:\begin{array}{c}Balanced\:Accuracy=\frac{Sensitivity+Specificity}{2}\end{array}$$
The bACC is the average sensitivity and specificity, providing a single metric that considers both types of classification errors. This is particularly useful for imbalanced datasets44.
Using these evaluation metrics, we comprehensively assessed the ability of our model to distinguish between HVs and patients. Each metric provides valuable insights into the different aspects of model performance, contributing to a robust evaluation framework.
Statistical analyses
To compare the ages of the HVs and patients, a one-way analysis of variance (ANOVA) was conducted across all groups. Post-hoc pairwise comparisons were subsequently performed using t-tests with the Bonferroni correction. Sex distribution was assessed using Fisher’s exact test. In the post-hoc analysis, assuming a two-tailed test with an effect size of 0.5, the power was calculated to be 96.8% for the sample sizes of HVs and patients. All tests were two-tailed, and the significance level was set at p < 0.05. Statistical analyses were conducted using Python (version 3.11.9) and the SciPy library (version 1.14.1).



Leave feedback about this